大家好呀。
因为之前有过字体解析的相关代码开发,一直想把这个过程记录下来,总觉得这个并不是很难,自认为了解得不算全面,就一拖再拖了。今天仅做简单的抛砖引玉,通过本篇文章,可以知道Opentype.js是如何解析字体的。在遇到对应问题的时候,可以有其它的思路去解决。比如:.ttc的解析。又或者好奇我们开发软件过程中字体是如何解析的。
Opentype.js 使用
看官方readme也可以,这里直接将github代码下载,使用自动化测试目录里的字体文件。
需要注意的是load方法已经被废弃。
function load() {
console.error('DEPRECATED! migrate to: opentype.parse(buffer, opt) See: https://github.com/opentypejs/opentype.js/issues/675');
}
将package.json设置为type: module,然后就可以直接使用import了。
import { parse } from './src/opentype.mjs';
import fs from 'fs';
// test/fonts/AbrilFatface-Regular.otf
const buffer = fs.promises.readFile('./test/fonts/AbrilFatface-Regular.otf');
// if not running in async context:
buffer.then(data => {
const font = parse(data);
console.log(font.tables);
})
Opentype源码阅读
parseBuffer:解析的入口
通过简单的调用入口,我们可以反查源码。传入文件的ArrayBuffer并返回Font结构的对象,当不清楚会有什么结构的时候,可以通过Font查看,当然了,直接console.log查看更方便。
// Public API ///////////////////////////////////////////////////////////
/**
* Parse the OpenType file data (as an ArrayBuffer) and return a Font object.
* Throws an error if the font could not be parsed.
* @param {ArrayBuffer}
* @param {Object} opt - options for parsing
* @return {opentype.Font}
*/
function parseBuffer(buffer, opt={}) {
// ...
// should be an empty font that we'll fill with our own data.
const font = new Font({empty: true});
}
export {
// ...
parseBuffer as parse,
// ...
};
字体类型判断
接着往下阅读。
根据signature的值,去确认字体类型。粗略看来,这里仅支持了TrueType(.ttf)、CFF(.otf)、WOFF、WOFF2。并不支持.ttc、.otc字体集合。
TrueType 为苹果和微软共同定制的,使用 二次贝塞尔曲线 来定义字形轮廓,高效兼容。CFF 分为版本1、2,最初用于 Adobe PostScript 打印机行业;sfntVersion 都是 OTTO;采用 三次贝塞尔曲线;可以封装 TrueType,压缩性更好的格式;CFF2 引入对可变字体字重、字宽、斜率的支持。如果 TrueType 和 CFF1 需要包含多字重等字体,通常可以打包成为 .ttc 和 .otc 字体集合的格式
简单的说,TTF 会使用 glyf 表存完整的字形,CFF1 则会有局部表存类似偏旁部首,以达到共享,CFF2 最直观的就是多个字重的单独字体,通过变量轴合并成一个字体。
const signature = parse.getTag(data, 0);
if (signature === String.fromCharCode(0, 1, 0, 0) || signature === 'true' || signature === 'typ1') {
} else if (signature === 'OTTO') {
} else if (signature === 'wOFF') {
} else if (signature === 'wOF2') {
} else {
throw new Error('Unsupported OpenType signature ' + signature);
}
值得一提的是,signature 的值获取的方式 getTag。从指定偏移位置开始,读取4个字节的数据,并将每个字节转换为字符,最终返回一个4字符的字符串标签。后续获取字段信息大部分都是通过类似的方式。
// Retrieve a 4-character tag from the DataView.
// Tags are used to identify tables.
function getTag(dataView, offset) {
let tag = '';
for (let i = offset; i < offset + 4; i += 1) {
tag += String.fromCharCode(dataView.getInt8(i));
}
return tag;
}
拿 OTTO 举例,二进制文件存储的其实是01001111 01010100 01010100 01001111 这样的 8bit = 1byte 的数据。
表入口信息获取
进入 if else 看TrueType和CFF字体的处理,对font.outlinesFormat属性的设置设置为不同的字体类型之后。接下来都是获取表的个数numTables,再获取表数据的入口偏移信息。
numTables = parse.getUShort(data, 4);
tableEntries = parseOpenTypeTableEntries(data, numTables);
// Table Directory Entries //////////////////////////////////////////////
/**
* Parses OpenType table entries.
* @param {DataView}
* @param {Number}
* @return {Object[]}
*/
function parseOpenTypeTableEntries(data, numTables) {
const tableEntries = [];
let p = 12;
for (let i = 0; i < numTables; i += 1) {
const tag = parse.getTag(data, p);
const checksum = parse.getULong(data, p + 4);
const offset = parse.getULong(data, p + 8);
const length = parse.getULong(data, p + 12);
tableEntries.push({tag: tag, checksum: checksum, offset: offset, length: length, compression: false});
p += 16;
}
return tableEntries;
}
function getUShort(dataView, offset) {
return dataView.getUint16(offset, false);
}
// Retrieve an unsigned 32-bit long from the DataView.
// The value is stored in big endian.
function getULong(dataView, offset) {
return dataView.getUint32(offset, false);
}
留意到tableEntries获取的 offset 是从 第12个字节开始的,而获取numTables是从第4第5两个字节(getUnit16),也就是说6-12之间还包含了别的信息。
表信息标准描述
这时候只能通过查看微软排版文档描述,Microsoft Typography documentation: Organization of an OpenType Font。
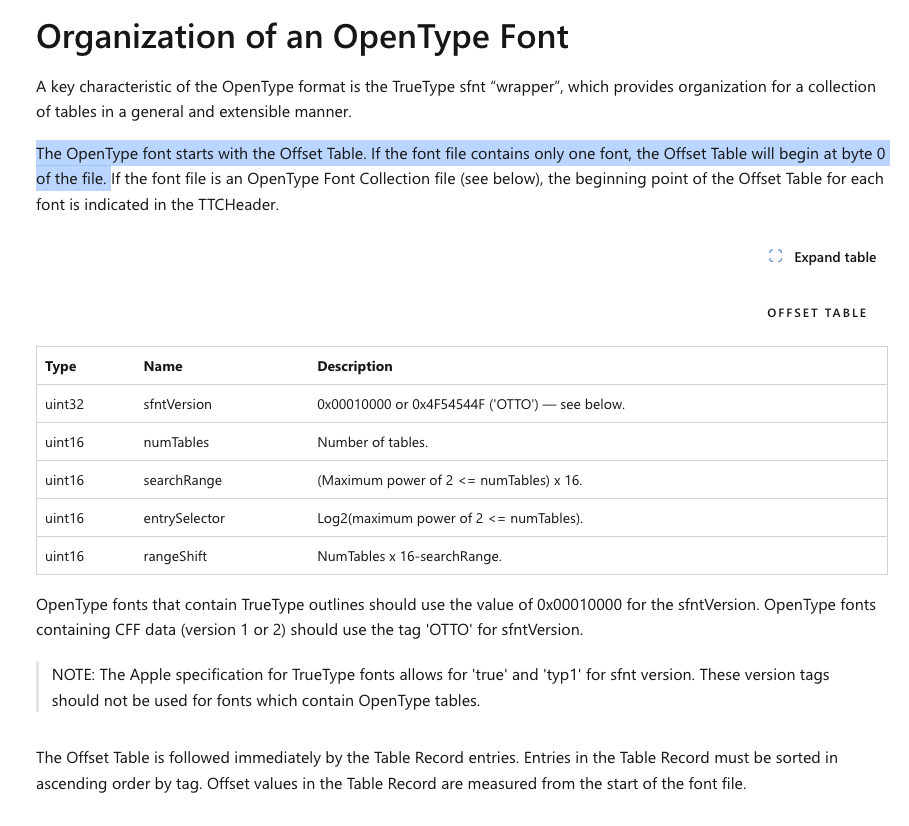 按照8bit计算,这些信息之后,刚好是在12个字节开始。
按照8bit计算,这些信息之后,刚好是在12个字节开始。
searchRange、entrySelector 和 rangeShift 是用于在字体文件中查找特定表的索引。依赖表的有序排列,不管有多少个表,使用二分都能比通过tableEntries 数组逐个查找快。
后续的描述就是parseOpenTypeTableEntries的结构信息了。
表入口数据
以选择的 AbrilFatface-Regular.otf 为例。我们可以打断点看看,这两步骤得到的结果,这里Opentype提供了网址,就直接在上面断点了。
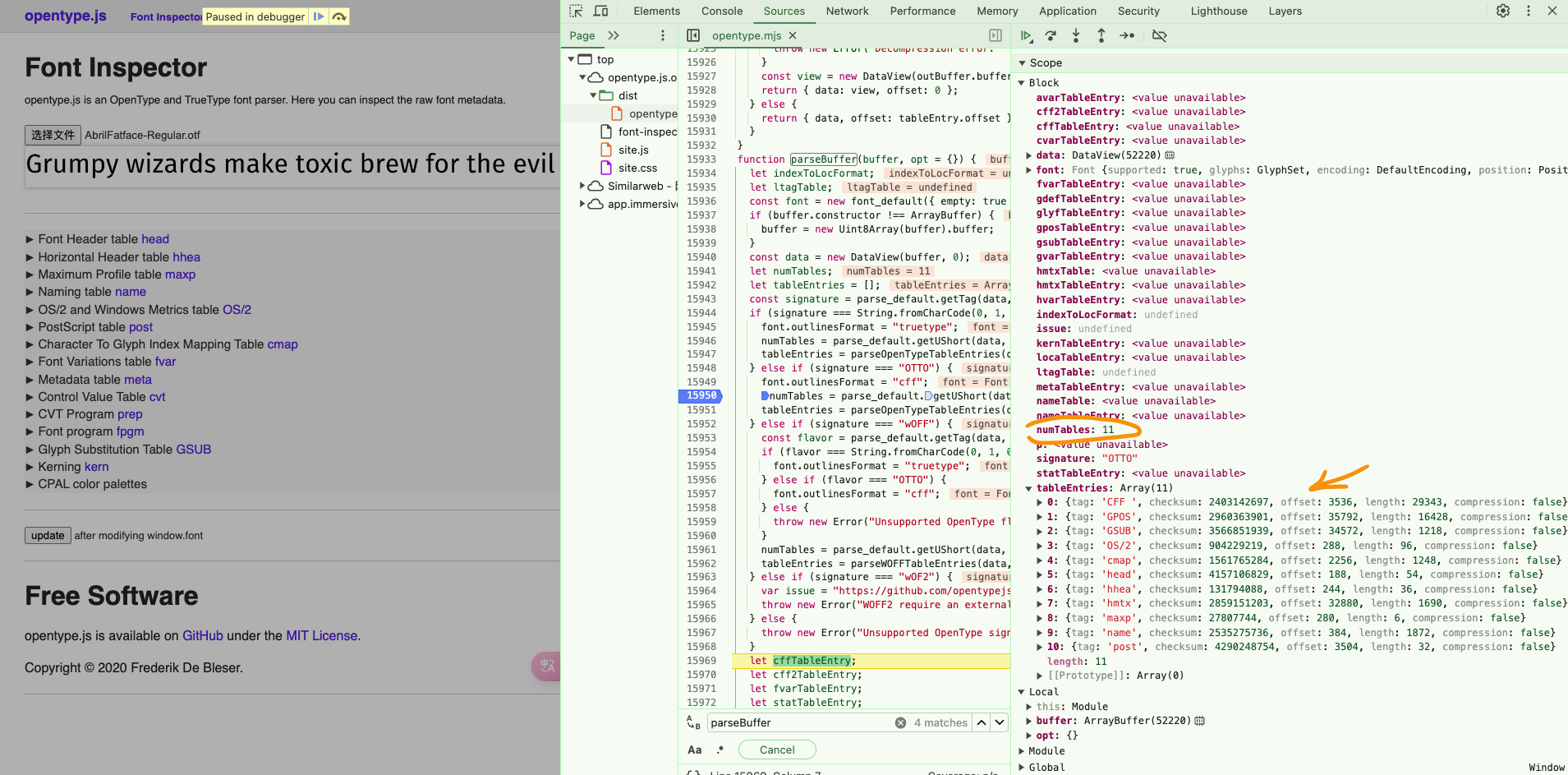
这里有11个表,在入口分别有对应的名称、偏移量、长度、校验和。
表数据解析
有了表入口信息,就可以通过tableEntries获取表的数据了。接下来的代码就是通过对应的tag(name)去选择对应的解析方式。有些表的信息需要依赖于别的表,则先暂时存起来。比如: name表需要依赖language表。
case 'ltag':
table = uncompressTable(data, tableEntry);
ltagTable = ltag.parse(table.data, table.offset);
break;
// ...
case 'name':
nameTableEntry = tableEntry;
break;
// ...
const nameTable = uncompressTable(data, nameTableEntry);
font.tables.name = _name.parse(nameTable.data, nameTable.offset, ltagTable);
font.names = font.tables.name;
这里就简单看下ltag表的解析,table = uncompressTable(data, tableEntry);判断是否有压缩,比如WOFF压缩字体,这里没有entry数据就还是原来的。
ltag表的解析
function parseLtagTable(data, start) {
const p = new parse.Parser(data, start);
const tableVersion = p.parseULong();
check.argument(tableVersion === 1, 'Unsupported ltag table version.');
// The 'ltag' specification does not define any flags; skip the field.
p.skip('uLong', 1);
const numTags = p.parseULong();
const tags = [];
for (let i = 0; i < numTags; i++) {
let tag = '';
const offset = start + p.parseUShort();
const length = p.parseUShort();
for (let j = offset; j < offset + length; ++j) {
tag += String.fromCharCode(data.getInt8(j));
}
tags.push(tag);
}
return tags;
}
创了p这个Parser实例,包含各种长度parseShort、parseULong等。自动移动offset,避免每次手动传入位置。获取了table的version信息,而后就是循环的获取表内容了。
不同表的具体信息,可以查阅文档。
解析小结
通过上述分析,我们可以初步了解字体的解析过程:它遵循 OpenType 规范的固定结构,从 Offset Table 开始,逐步解析表入口和表数据,像“剥洋葱”一样层层深入,最终提取所需信息。
例如,要获取某个字的 SVG 路径,就可以通过 cmap 表(unicode)获取字符对应的字形索引,在 glyf、CFF 表获取贝塞尔曲线点的数据,转换为 SVG。印象中 opentype.js 提供了 getPath 转 SVG 的方法,可以断点尝试看看~
TTC字体集合的解析
回到前面提出的,ttc字体集合,应该怎么解析呢?参照文档对字体集合的处理 Font Collections,相信大家已经有办法解析了。
 注意:这里截图给出的是1.0的结构,更多的查看文档。
注意:这里截图给出的是1.0的结构,更多的查看文档。
最后
这次的分享就到这里了,对一些有按需解析,自定义解析的场景下,希望对大家有帮助。