我花三个月复刻了个 $30/月 的产品,然后推翻了自己
我没付那 $30。不是付不起,是不服气。一个语音识别加大模型后处理,凭什么收这个价?我一个开发者,自己搞不定吗?
三个月后,我不仅搞定了,还把自己之前的判断推翻了大半。
今天这篇,不是产品评测,也不是教程。我想聊聊在这个过程里,我真正想清楚的一件事:在 AI 让所有人都能低成本实现“标准流程”的今天,产品的壁垒到底是什么?
一、“不就是 ASR + LLM”——我太天真了
先说背景。去年到现在,语音输入这个赛道突然热起来,导火索是一个叫 Typeless 的产品。月费 ,年度折合12/月。
各路人都在做类似的东西:智谱、豆包在免费铺量,闪电说在极客上越走越深,我自己也跳进来了。
我最初的判断很简单:这玩意儿技术上没有门槛,采集语音 → ASR 转文字 → LLM 后处理,三步走,套壳产品而已。
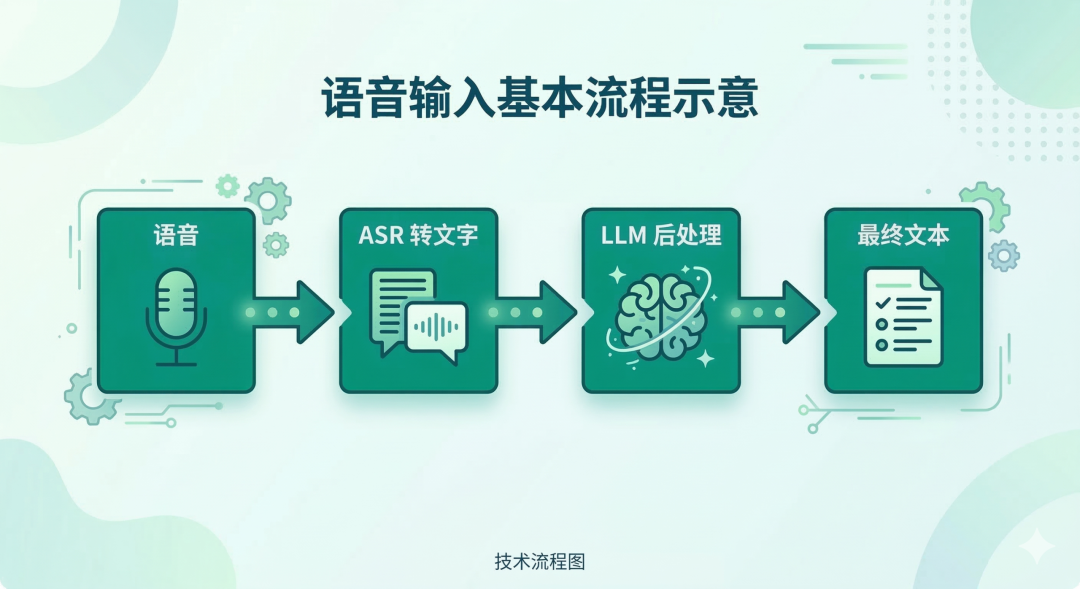
于是我自己动手做了一个,要求还挺高:数据安全、全本地离线。
很快就被现实教育了。
第一关:本地模型各有死角。
闪电说默认用的是阿里开源的 SenseVoice Small,这个模型在纯中文下比 Whisper 有优势,速度也快。但我的日常是开发者的中英夹杂——“这个 PR 要 fix 一下 memory leak”——碰到这种场景,SenseVoice Small 就开始发挥不稳定了。Whisper 的问题则反过来,英文强,中文弱。
两个本地模型,各有各的死角,没有一个能覆盖我的真实场景。
第二关:算力不可能在本地。
本地既要跑 ASR 又要跑 LLM,我的电脑还要不要干活了?高智能算力天然属于远端,这不是观点,是成本规律。
第三关:语音和键盘,是两种完全不同的思维模式。
《思考,快与慢》里说人类有两套认知系统:一套快速、直觉、不费力;一套缓慢、理性、需要专注。
语音输入用的是前者——快,但全是口水词、重复、跳跃。
键盘输入逼着你用后者——打字的过程中,大脑自动帮你格式化语言。
这道鸿沟,就是 LLM 后处理存在的理由。它不是锦上添花,是刚需。
二、准确率的价值,不是你想的那样
当时我有一个很自然的判断:ASR 识别越准,后处理压力越小;前面错了,后面 LLM 要花更多智能去弥补。
这个逻辑本身没错。但做着做着,我发现真正要担心的不是“噪声”,而是“语义偏移”。
信息论告诉我们:一段话所携带的信息总量是固定的。口语里的口水词、重复、不连贯,LLM 完全有能力从中提取核心信息——这本来就是大模型擅长的事。所以 ASR 阶段有点噪声,不是致命问题。
真正致命的,是语义层面的不可逆偏移。
举个我自己遇到的真实案例:我在说“PLG 产品推动增长”,ASR 把它识别成了“PLC”。
PLC 是工业控制器,和 PLG 完全不是一个领域的东西。但这个识别结果本身是合理的——PLC 确实存在,语音上两者也确实相近。
问题在于,这个错误往下游传递之后,LLM 没有任何办法知道这是识别错误。它会基于“PLC”去理解、去执行,整个后续的逻辑链全部偏了。
这不是噪声,是错误信息被当成事实向下传递。
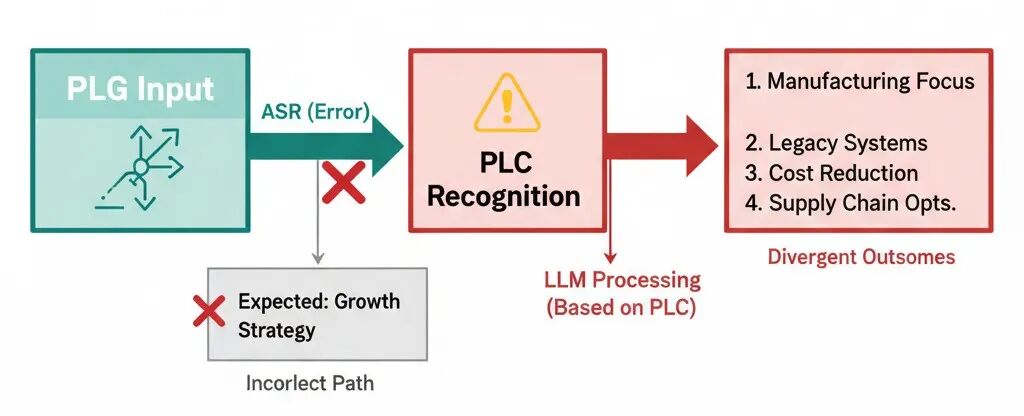
类似的还有:Typeless 被识别成 Tabless,Claude Code 被识别成云 Code。每一个都是语义上的隐性错误,越往下游走,纠正成本越高。
所以准确率的真正价值,不是给 LLM 省事,而是防止系统在错误的语义上越走越远。
三、我做了两个“完美功能”,然后把它们都砍掉了
深挖下去之后,我开始理解 Typeless 那 $30 背后的门道了:ASR 的调参地狱、热词的前置后置、双流实时处理的设计取舍……每一个细节都是脏活。它替用户把这些全吃掉了。
但我还是觉得自己能做得更好,于是加了两个功能,又把它们都砍了。
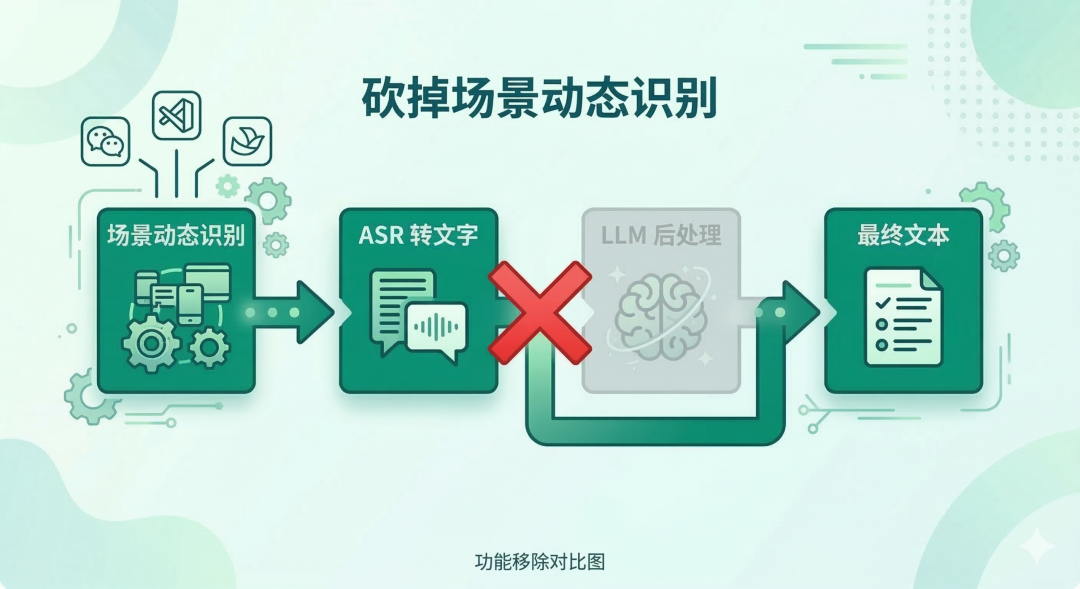
第一个被砍的:场景动态识别。
想法是这样的:根据用户当前打开的软件,自动切换后处理风格。在飞书就用职场风润色,在微信就保留口语感,在代码编辑器里识别到指令就直接执行。
听起来很完美。
但越想越不对。这个功能要真正好用,用户得自己配置不同场景的提示词,得理解“职场风”和“口语风”的差别,得记住不同场景触发不同快捷键。每一步都在消耗用户的注意力,本质上是把复杂度转嫁给了用户。
更大的问题是:提示词一旦配错,或者场景判断出了偏差,后处理出来的文本语义就会被改变。我们在 ASR 层好不容易保住的语义准确性,在后处理层自己给破坏掉了。
这个功能表面上是“更聪明”,实际上是新的风险来源。砍。
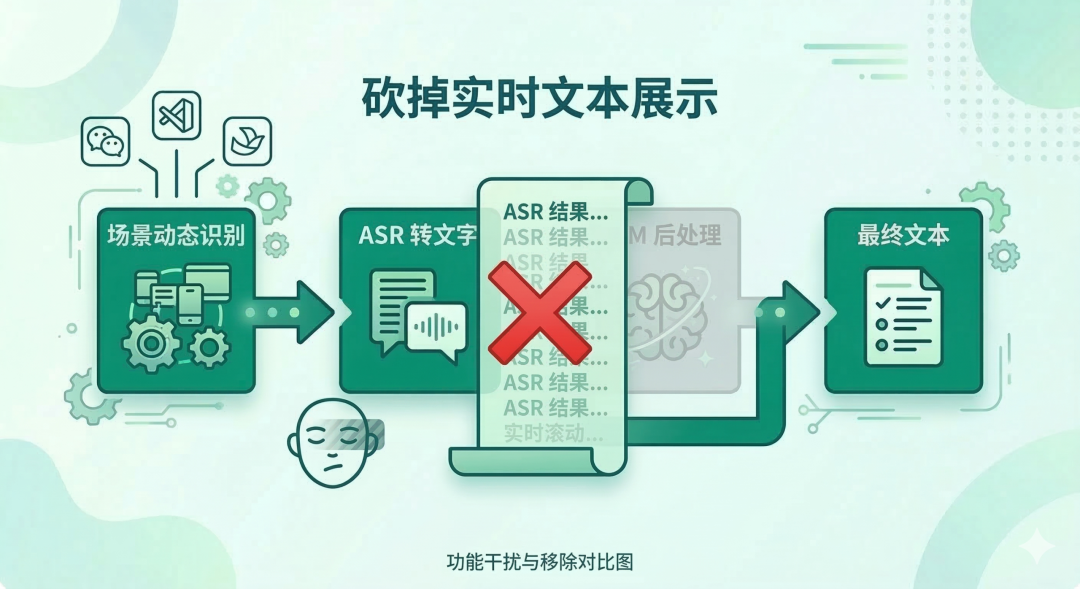
第二个被砍的:实时 ASR 文本展示。
双流实时 ASR 可以一边说一边把识别结果显示出来,我当时觉得体验感很强。
结果一个朋友用了之后说:那些实时滚动的文字他完全不看,但那个界面侵占感让他很不舒服。他说:“我只需要知道它在跑,最后给我结果就行,中间过程我不 care。”
这句话点醒了我。
我一直在想怎么让产品“更聪明”、“更透明”,但用户真正要的,是更不打扰。这是两个完全不同的方向,而且前者恰恰是对后者的伤害。
这两次砍功能,是我在这个项目里做的最正确的两个决策。
四、Typeless 的那道缝
理解了它为什么值钱,我开始想它的边界在哪里。
Typeless 面对全球 C 端用户,它的模型权重里,“感冒”的识别优先级一定远高于“特发性肺纤维化”。哪怕它用了全球最好的 ASR 接口,在医疗场景下,它对专业术语的识别准确率就是不如一个针对医生微调过的模型。
同理,法律、金融、工程领域,都有大量大众词汇权重低、专业术语权重高的场景。

这是顶流产品天然的盲区:为了覆盖 80% 的大众用户,它不可能为 20% 的垂直场景,牺牲哪怕 0.1% 的大众体验。
而这 20%,恰好是企业愿意付费的地方。
一个主任医师,没有时间研究 ASR 接口、API Key、热词权重。他只知道:说了一堆术语,出来全是错别字,这工具没法用。但如果有一款工具,开箱即用,专门为医疗场景做过调教,他愿不愿意用?
什么样的调教?不是只用某一个“最好的”模型,而是知道什么时候用阿里的 ASR 对中文更准,什么时候用 Deepgram 对中英混输更友好,甚至同一句话里能根据语境动态路由。这件事自己折腾一遍至少一星期,我替他选好。
这就是那道缝。
不是靠功能创新挤进去的,而是靠愿意替某一个具体的群体,把那些没人愿意做的脏活吃干净。
后面我会专门写一篇,聊聊 ASR 选型里那些没人愿意讲的脏活——为什么没有“最好的模型”,只有“最合适的模型”。
五、我从中看到的,不只是语音输入法这件事
在 AI 让所有人都能低成本实现“标准流程”的今天,如果你的业务是标准的,你随时可能被一个用 AI 重新实现了你流程的竞争对手替掉。他们不需要比你更好,只需要更便宜,或者界面更顺手。
这类产品最需要做的一件事,是尽快让自己的服务变成 Agent 可调用的形式,把定价权握在自己手里。要不然,你的标准流程就是别人的训练素材。
反过来,越混乱的流程,越需要有人下场去定义它。能做到这件事的,不是掌握了最厉害技术的人,而是对某个具体的混乱角落有足够深的理解,并且愿意一件一件把那些说不清楚的脏活干完的人。
这是我从做语音输入法这件小事里,看到的一个略大一点的东西。
我还在做这个产品,Alpha 阶段,很多地方没想清楚。但我想把这个过程公开出来,持续迭代,持续写下去。
如果你也在某个垂直行业被现有工具折磨,或者你也在 AI 时代找自己的那道缝,欢迎来聊。
下篇见。
修改于